Exploratory Data Analysis
Dataset Overview
A realistic synthetic e-commerce dataset modeled on the Kaggle E-Commerce Customer Churn benchmark,
covering behavioral, satisfaction, demographic, and multi-channel marketing signals.
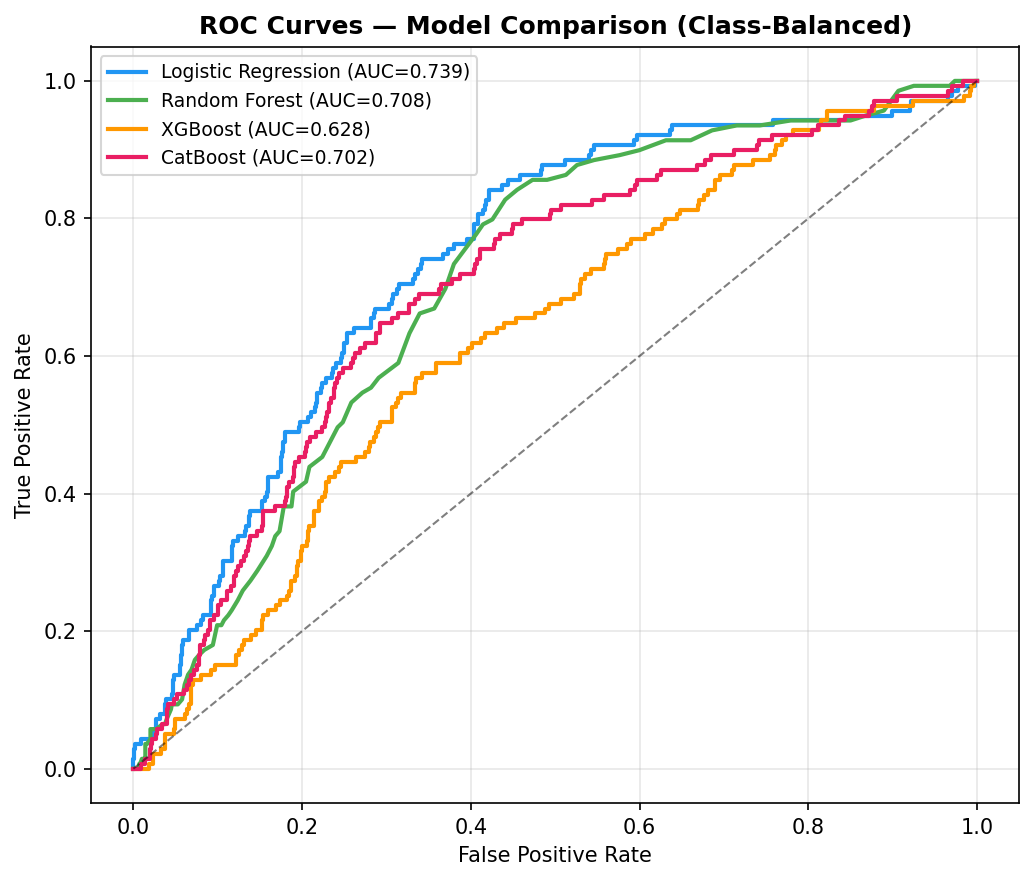
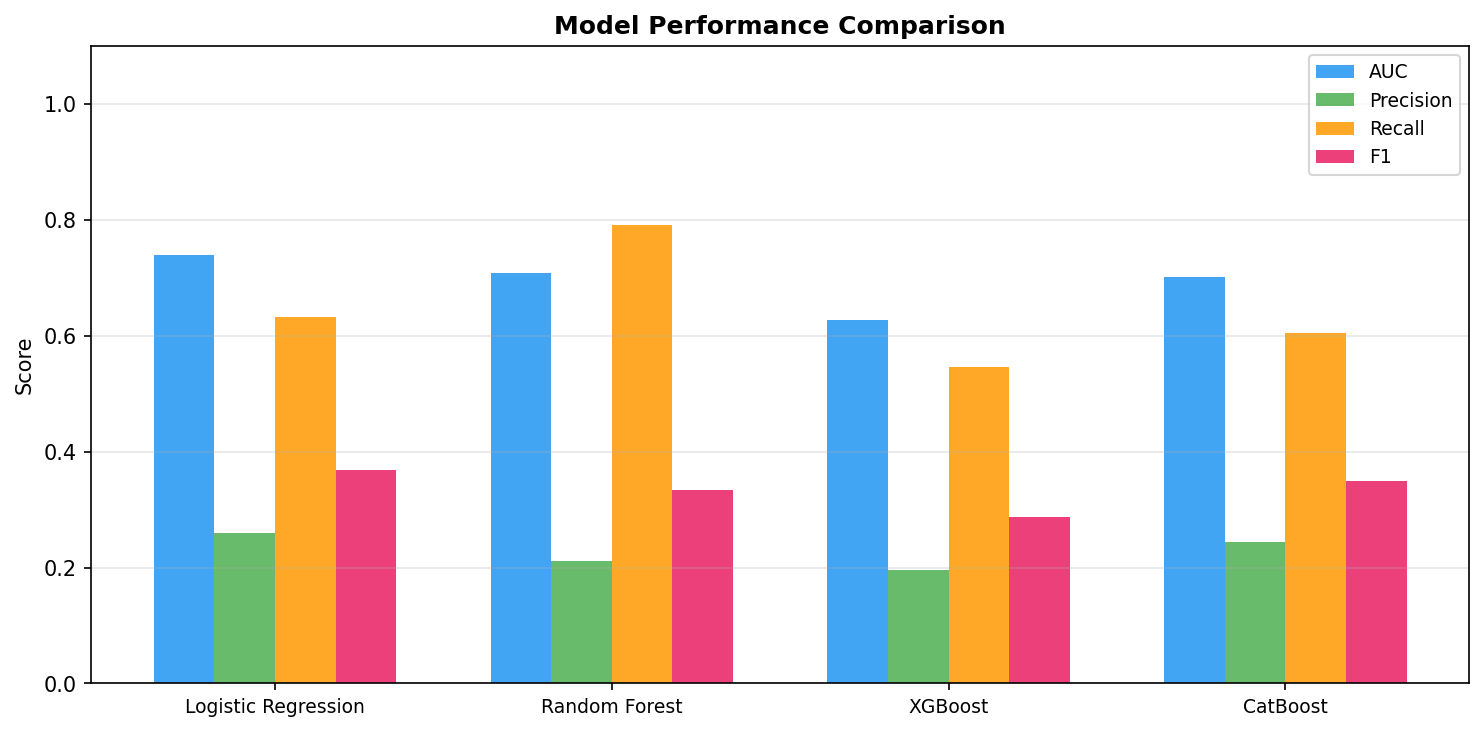
Class imbalance (~12.3% churn) was handled via class_weight='balanced' and PR-curve threshold tuning.
Feature Groups
| Category | Key Features |
|---|---|
| Behavioral | Tenure, OrderCount, DaySinceLastOrder, CouponUsed, CashbackAmount |
| Satisfaction | SatisfactionScore, Complain |
| Demographics | Gender, MaritalStatus, CityTier, NumberOfAddress |
| Marketing Channels | EmailOpens, EmailClicks, PushNotifClicked, SocialAdClicked, RetargetingExposed, AcquisitionChannel |
| Engineered | EmailEngagementRate, MultiChannelEngagement |
Key EDA Findings
▲
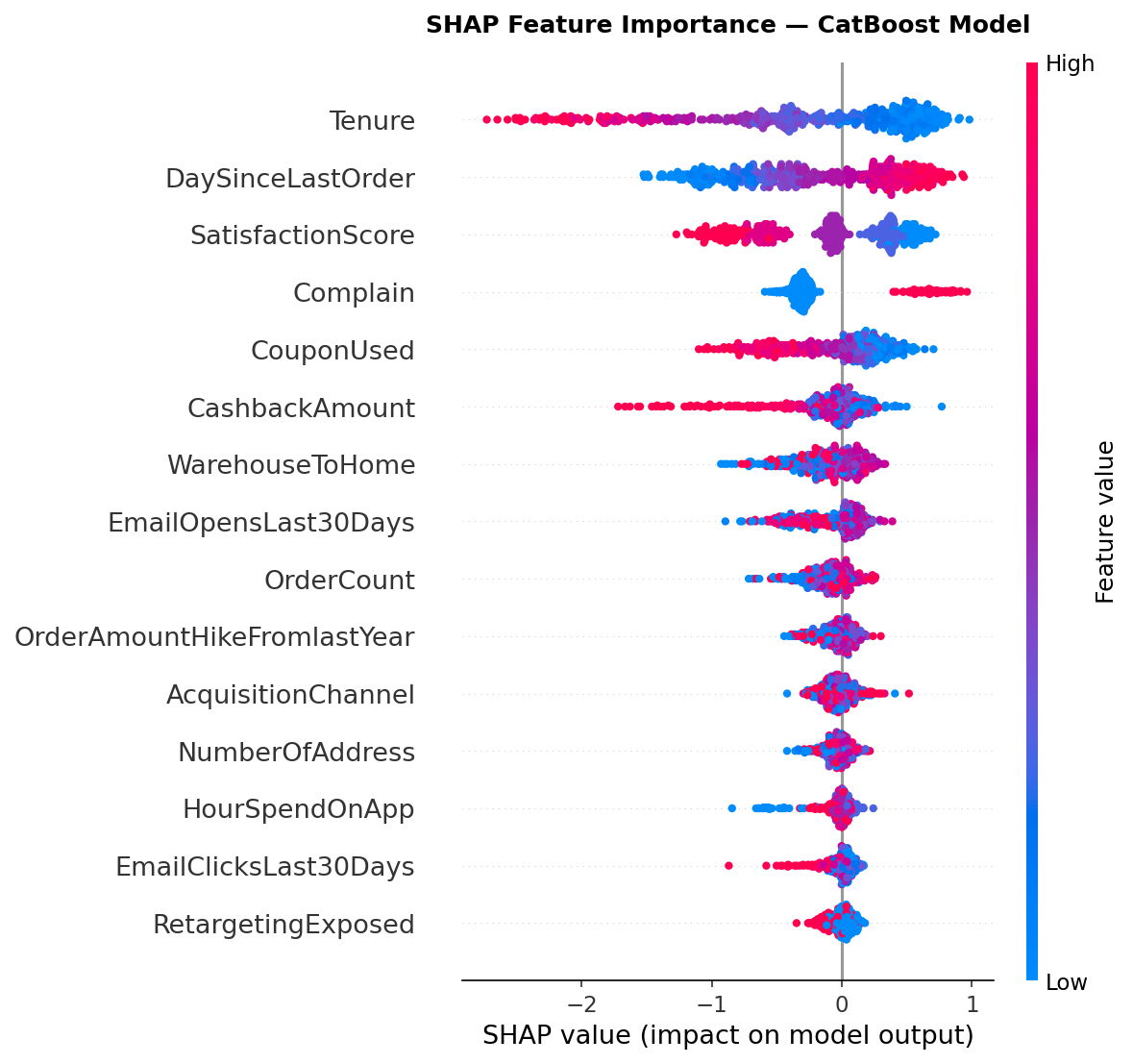
Paid Search & Social acquisition channels show the highest churn rates
▲
Customers with low tenure (<6 months) are dramatically higher risk
▼
Email engagement (clicks/opens) is negatively correlated with churn
▲
Customers with complaint history have materially higher churn probability
●
Recency (DaySinceLastOrder) is a strong leading indicator — even before cancellation
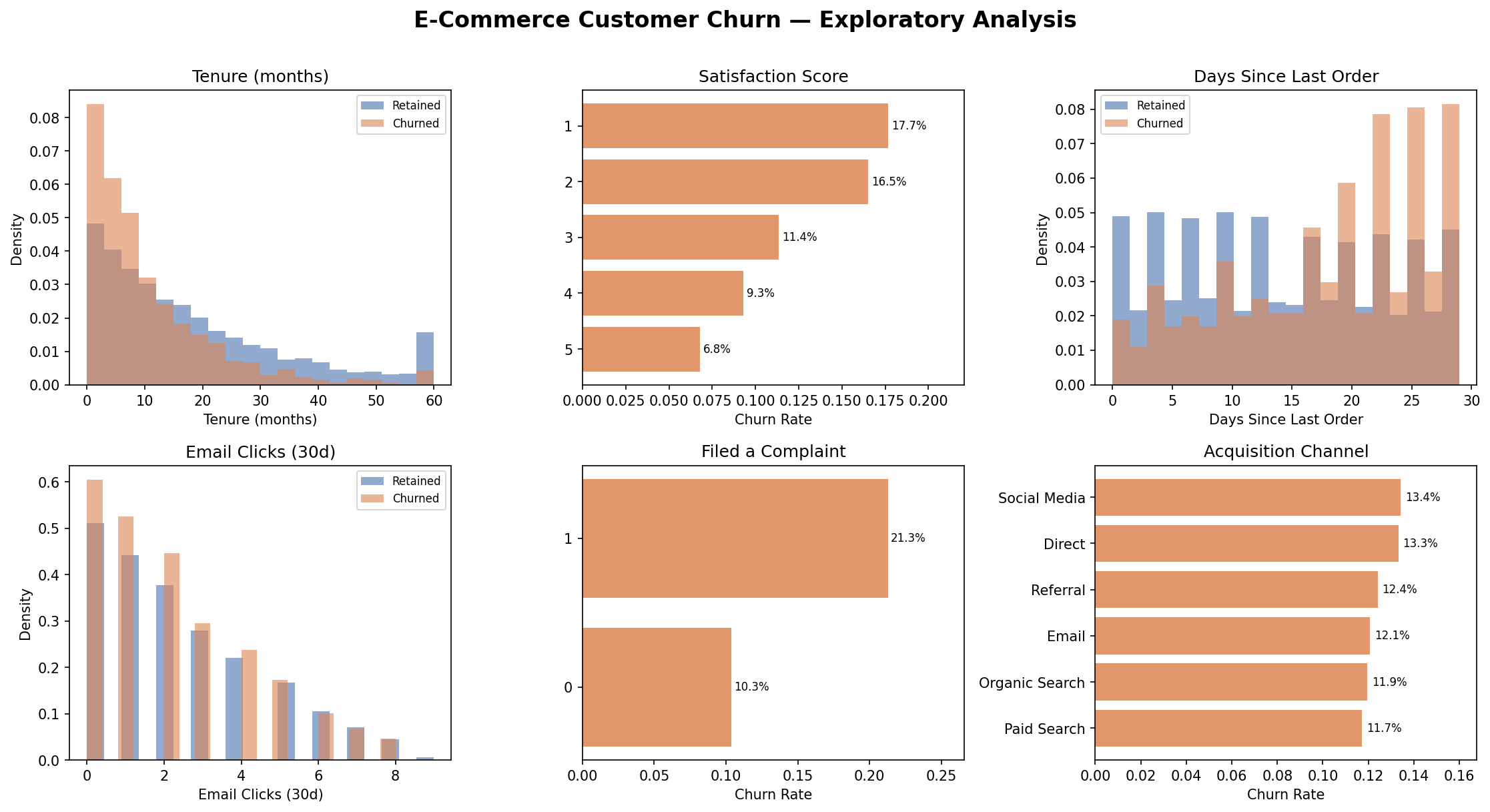
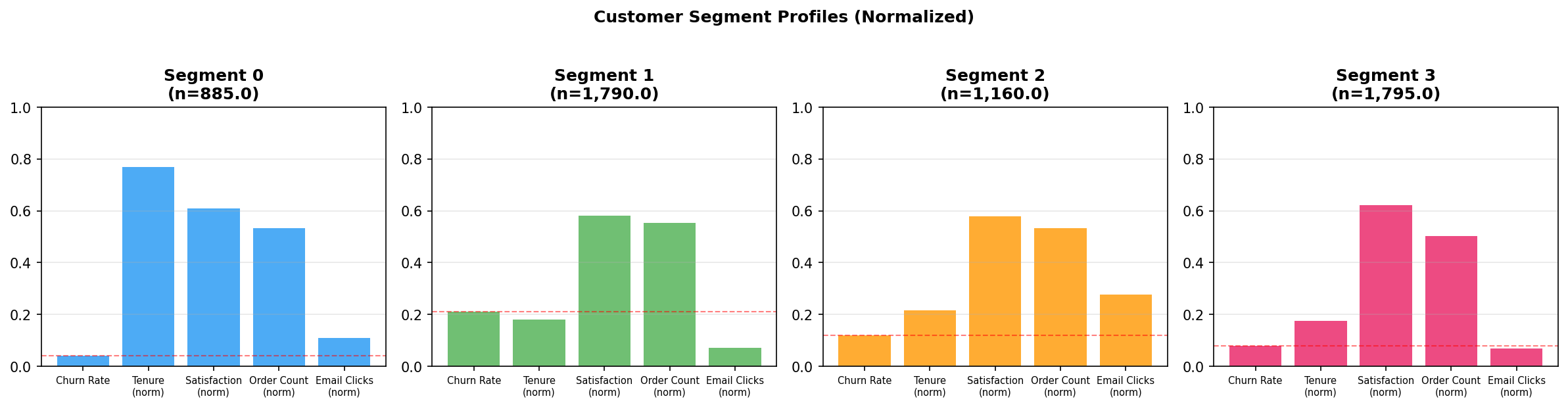
Figure 1: Exploratory data analysis — churn rates by acquisition channel, marketing engagement distributions, and feature correlations.